
")
K-nearest neighbors atau knn adalah algoritma yang berfungsi untuk melakukan klasifikasi suatu data berdasarkan data pembelajaran (train data sets), yang diambil dari k tetangga terdekatnya (nearest neighbors). Dengan k merupakan banyaknya tetangga terdekat.
A. Cara Kerja Algoritma K-Nearest Neighbors (KNN)
K-nearest neighbors melakukan klasifikasi dengan proyeksi data pembelajaran pada ruang berdimensi banyak. Ruang ini dibagi menjadi bagian-bagian yang merepresentasikan kriteria data pembelajaran. Setiap data pembelajaran direpresentasikan menjadi titik-titik c pada ruang dimensi banyak.
A1. Klasifikasi Terdekat (Nearest Neighbor Classification)
Data baru yang diklasifikasi selanjutnya diproyeksikan pada ruang dimensi banyak yang telah memuat titik-titik c data pembelajaran. Proses klasifikasi dilakukan dengan mencari titik c terdekat dari c-baru (nearest neighbor). Teknik pencarian tetangga terdekat yang umum dilakukan dengan menggunakan formula jarak euclidean. Berikut beberapa formula yang digunakan dalam algoritma knn.
-
Euclidean Distance
Jarak Euclidean adalah formula untuk mencari jarak antara 2 titik dalam ruang dua dimensi.

-
Hamming Distance
Jarak Hamming adalah cara mencari jarak antar 2 titik yang dihitung dengan panjang vektor biner yang dibentuk oleh dua titik tersebut dalam block kode biner.
-
Manhattan Distance
Manhattan Distance atau Taxicab Geometri adalah formula untuk mencari jarak d antar 2 vektor p,q pada ruang dimensi n.
-
Minkowski Distance
Minkowski distance adalah formula pengukuran antar 2 titik pada ruang vektor normal yang merupakan hibridisasi yang menjeneralisasi euclidean distance dan mahattan distance.
Teknik pencarian tetangga terdekat disesuaikan dengan dimensi data, proyeksi, dan kemudahan implementasi oleh pengguna.
A2. Banyaknya k Tetangga Terdekat
Untuk menggunakan algoritma k nearest neighbors, perlu ditentukan banyaknya k tetangga terdekat yang digunakan untuk melakukan klasifikasi data baru. Banyaknya k, sebaiknya merupakan angka ganjil, misalnya k = 1, 2, 3, dan seterusnya. Penentuan nilai k dipertimbangkan berdasarkan banyaknya data yang ada dan ukuran dimensi yang dibentuk oleh data. Semakin banyak data yang ada, angka k yang dipilih sebaiknya semakin rendah. Namun, semakin besar ukuran dimensi data, angka k yang dipilih sebaiknya semakin tinggi.
A3. Algoritma K-Nearest Neighbors
- Tentukan k bilangan bulat positif berdasarkan ketersediaan data pembelajaran.
- Pilih tetangga terdekat dari data baru sebanyak k.
- Tentukan klasifikasi paling umum pada langkah (2), dengan menggunakan frekuensi terbanyak.
- Keluaran klasifikasi dari data sampel baru.
B. Contoh Aplikasi K Nearest Neighbors
Contoh berikut diambil dari buku "Data Science Algorithms in a Week" yang ditulis oleh Dávid Natingga.
Pada contoh ini, dilakukan klasifikasi suhu udara berdasarkan persepsi seseorang yang bernama Marry. Adapun klasifikasi suhu udara terdiri dari 2 persepsi yaitu Panas dan Dingin. Persepsi ini dapat diukur berdasarkan 2 variabel yaitu temperatur dalam derajat celcius dan kecepatan angin dalam km/h. Diperoleh data berikut,
| Temperatur Udara (ºC) | Kecepatan Angin (km/jam) | Klasifikasi atau Persepsi Marry |
| 10 | 0 | Dingin |
| 25 | 0 | Panas |
| 15 | 5 | Dingin |
| 20 | 3 | Panas |
| 18 | 7 | Dingin |
| 20 | 10 | Dingin |
| 22 | 5 | Panas |
| 24 | 6 | Panas |
Untuk contoh ini terbentuk ruang dimensi 2, yang berisi 2 kriteria yaitu temperatur udara dan kecepatan angin.
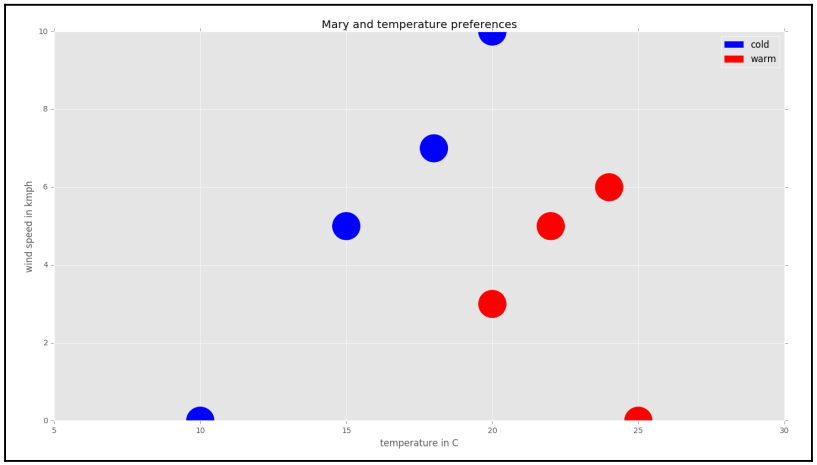
Pada proyeksi di atas sumbu vertikal adalah kecepatan angin, sumbu horizontal adalah temperatur suhu, warna biru adalah dingin, dan warna merah adalah panas.
Dari proyeksi di atas, dapat dilakukan klasifikasi data baru. Misalnya, Bagaimana persepsi Marry saat temperatur udara 16°C dan kecepatan angin 3 km/jam.
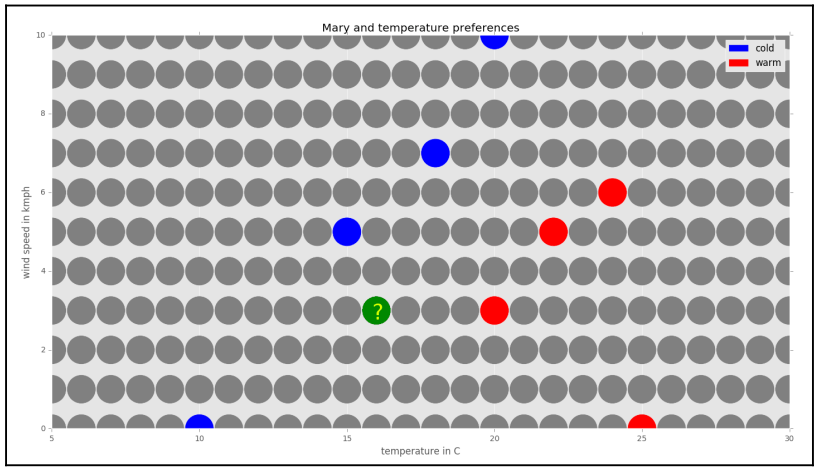
Proses pencarian tetangga terdekat
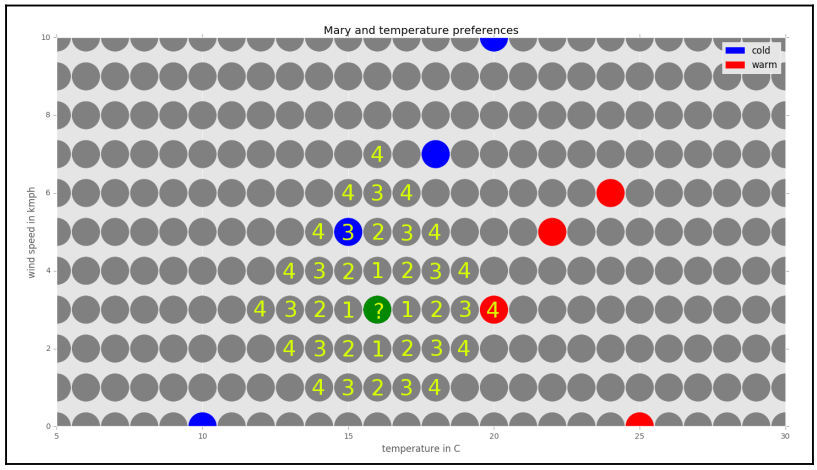
Dapat diketahui tetangga terdekatnya adalah titik c dingin dengan temperatur 15°C dan kecepatan angin 5 km/jam. Jadi berdasarkan pemilihan k = 1, klasifikasinya adalah dingin.
Dengan melakukan proses di atas terhadap semua titik, diperoleh proyeksi klasifikasi berikut.
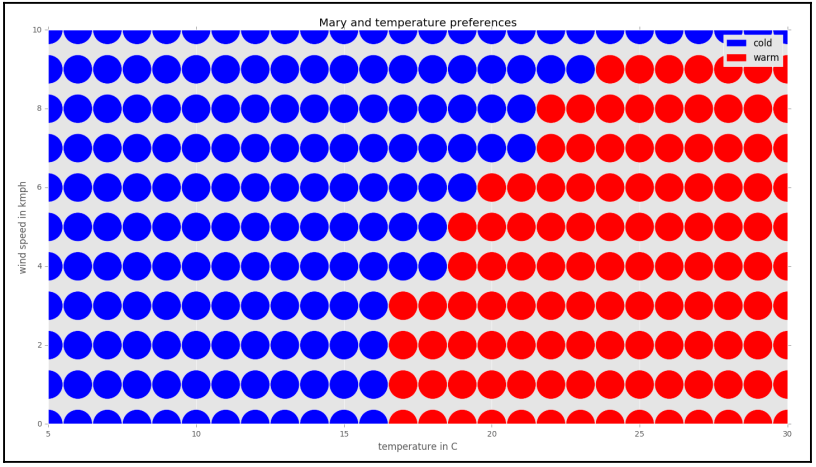
Catatan: Untuk pemilihan k lainnya, hasil klasifikasi ditentukan dengan frekuensi terbanyak. Misalnya k = 3, dengan titik terdekat dingin, panas, dingin. Hasil klasifikasi data baru tersebut adalah dingin.
Baca juga tutorial lainnya: Daftar Isi Machine Learning
Sekian artikel Pengertian dan Cara Kerja Algoritma K-Nearest Neighbors (KNN). Nantikan artikel menarik lainnya dan mohon kesediaannya untuk share dan juga menyukai halaman Advernesia. Terima kasih…






Kak mau tanya kalau kasusnya seperti ini bagaimana..
Semisal ada 3 jenis...
Bunga distance
A 2
B 2,5
B 2,5
B 3
A 3,5
A 4
C 5
C 5,5
C 6
Untuk k= 5..
Hasilnya termasuk bunga A atau bunga B?
Untuk kasus di atas
Misalkan knn = x,d untuk x = 5 diperoleh
A,2
B,2.5
B,2.5
B,3
A,3.5
Klasifikasi = B, diambil dari frekuensi terbanyak...
Semoga membantu kak Ayu...
Mbak mau tanya untuk kasus pengelompokan usia produktif dari beberapa thn terakhir cocok ga pake metode ini? Misal data dri thn 2013 - 2018 = 5 thn, didalamnya terdapat banyak usia yg mau dikelompokan. Masih pemula, mohon sarannya mbak🙏
pengelompokan usia produktif… usia produktif sudah mempunyai interval usianya kan mbak… jadi bagian apanya yang mbak mau klasifikasi?
Maaf mbak mau nanya kalo klasifikasi golongan darah datanya berupa gambar ekstraksi cirinya menggunakan PCA ,kira2 biga gak ya pakai k-nn
Menurut saya bisa mbak, tapi saya belum pernah mencobanya. Namun, saya lihat beberapa artikel menjelasakan k-NN dapat digunakan sebagai metode untuk melakukan image processing.
Semoga bermanfaat 🙂
kak mau nanya, apakah penerapan algoritma knn bisa diterapkan dalam penyeleksian calon siswa ataupun mahasiswa baru?
Penyeleksian calon siswa saya belum pernah melihatnya kk. Menurut saya, penyeleksian calon siswa mempunyai fungsi pembatas berdasarkan kecil besarnya nilai setiap data, sedangkan knn untuk melakukan klasifikasi apakah data A diterima atau tidak saja, tidak menyangkut penerimaan data secara menyuluruh, mungkin perlu dilakukan modifikasi metode.
Semoga dapat menjadi pertimbangan kak Fakhri 🙂
Selamat malam, mau tanya apakah KNN bisa digunakan untuk prediksi penjualan? jika iya apa saja yg dibutuhkan? bisa dishare link untuk materi?
terima kasih
Selamat malam kak dikha Hariyanto, saya juga masih mempelajari hal ini kak. Menurut saya penjualan merupakan data dalam jenis time-series. Walaupun KNN biasanya digunakan pada data yang bersifat cross-sectional, banyak terdapat jurnal-jurnal dengan metode knn untuk melakukan analisis data time-series. Jadi, itu bisa dilakukan kak.
Menurut saya untuk melakukannya, data tujuan perlu dilakukan clustering terlebih dahulu. Namun, mohon maaf di Advernesia belum menyediakannya..
Secepatnya saya akan mempelajari dan kemudian membuat tutorialnya 🙂
Terima kasih kakak Dikha 🙂
Mau tanyak jika ada data kayak gini
1 : 25.5 kel.1
2 : 25.6 kel.2
3 : 22 kel.1
4 : 18 kel.3
5 : 20 kel. 4
Nah kalau ssperti data di atas 25.5 dan 25.6 angkanya sama tapi masuk di kelompok berbeda, untuk menentukan K=5 bagai mna kak?
Untuk k=5, hasilnya kel 1... kak Linda
Karena kel 1 jenis tetangga paling banyak.
Semoga membantu 🙂
Apakah ada fungsi python yang digunakan untuk menconvert data float ke int mas?. Setau saya data knn itu harus int
K-NN data kelas klasifikasi nilainya harus integer tapi type datanya bisa digunakan float mas, data variabel lainnya nilainya boleh float. Misalnya, klasifikasi A = 1.000, B = 2.000, C = 3.0000. Jika menggunakan Python mas bisa melakukan konversi data ke numpy Array.
Semoga membantu kak 🙂
mbak bisa kasih saya contoh dalam bentuk file Ms office Excel ?
Maaf kak Dadang, membuat formula KNN dengan Microsoft Excel memerlukan kemampuan VBA, saya belum memahaminya. Saya biasa menggunakan Bahasa Python untuk melakukannya. Disamping itu, juga tersedia modul skicit-learn untuk memudahkan analisisnya. 🙂
kak itu pake aplikasi apa ya??
Terima kasih kak paijo atas komentarnya.
Ini merupakan algoritma pemrograman… kakak bias build programnya sendiri dengan Bahasa pemrograman yang kakak sukai…
untuk mempermudah kakak bisa menggunakan Python dengan skicit learn module...
nanti akan saya buat tutorialnya secepatnya kak
Semoga bermanfaat
kalau misalkan data sperti ini gimana kak?
k=3, hasil perhitungan :
jarak 8.944, rangking 1, status penilaian baik.
jarak 17,916, rangking 2, status penilaian sangat baik.
jarak 19,468, rangking 3, status penilaian cukup
jadi hasil klasifikasinya gimana kak?
Terima kasih kak Novi Permadi atas komentarnya...
Karena k hanya 3, jadi jarak yang paling dekat yang digunakan
Hasil klasifikasi pada jarak 8.944
Hai mba, mau tanya. Kalau metode ini dilakukan untuk olah teks, ada saran baiknya bagaimana gak mba? terima kasih
Terima kasih kak Adismutiaraa, untuk olah teks yang bagaimana maksud kk? text classifying, text recognition, atau apa?
Untuk character recognition pada gambar knn bagus atau tidak dibandingkan dengan menggunakan neural network?
Lebih baik dengan neural network menurut saya kak Anggoro...
Karena gambar mempunyai dimensi data yang besar...
Terima kasih atas komentarnya kak Anggoro 🙂
Halo kak selamat sore, kak saya ingin bertanya kalo untuk kelebihan dan kekurangan-nya K-NN itu sendiri apa ya kak, terus aku nemu data nih kak tapi dia memiliki kriteria nya lebih dari 2, nah caara hitung nya gimana ya kak?
Saya pernah baca tentang rumus euclidean distance bagus untuk dimensi < 10, kakak bisa menggunakan euclidean distance multidimensi. Kalau lebih banyak kriteria saya sarankan menggunakan metode jarak lain seperti manhattan distance. KKN kekurangannya menurut saya, dia sangat boros resource untuk melakukan komputasi data dan sering disebut lazy algorithms. Semoga membantu kak Kazan, saya juga masih belajar 🙂
bagaimana cara mengolah data tweet menggunakan knn?
Bisa diberikan penjelasan lebih lanjut kak?
kak kalau datanya banyak itu bagai mana kak, misal data nilai sekolah untuk menentuka jurusan kuliah, kan lebih dari 2 nilai tuh.
misal:
B. INDO MTK B.ING JURUSAN
80 90 89 AKUNTANSI
60 89 79 MANAJEMEN
70 87 68 PERBANKAN
bagaimana menentukan x,y nya,dan cara menghitungnya
Untuk 3 variabel, dapat menggunakan rumus euclidean di R3,
d = \/(x2-x1)2+(y2-y1)2+(z2-z1)2
Semoga bermanfaat 🙂
Kak kalo gini jawabanya gimana ya?
Prediksi Kelulusan Mahasiswa, setelah di hitung k=3 maka jawabannya itu gimana??
3.74 Lulus
4.12 Gagal
4.24 Remidi
3.74 Lulus
4.12 Gagal
4.24 Remidi
4.89 Lulus
5.38 Remidi
6 Gagal
6.16 Gagal
6.48 Lulus
6.70 Remidi
Biasa tinggal urutkan jarak terdekat, pilih frekuensi terbanyak. jika k=3 masih ambigu, algoritma knn akan meningkatkan k+1 atau mengurangi k-1 untuk kasus ambigu
Semoga bermanfaat
mbak saya mau nanya , apakah algoritma knn bisa digunakan untuk memprediksi penjualan di masa yang akan datang?
terima kasih kak
KNN merupakan algoritma klasifikasi. Saya tidak merekomendasikan untuk menggunakan kasus penjualan (time series) untuk KNN.
Namun, saya juga tidak dapat memastikan apakah KNN dapat digunakan untuk kasus penjualan. Jika pun tetap ingin menggunakan, mungkin data nya perlu di transformasi menggunakan metode "sliding window transformation", selain itu untuk meningkatkan performa, metode train:test sebaiknya diganti dengan "walk forward validation".
Semoga bermanfaat 🙂
kak mau tnyak, kalo K-NN untuk menentukan pengembangan karir siswa SMK bisa ga, kalo emng bisa variabel apa2 aja dimasukkan untuk mendapatkan titik hasilnya
mungkin nilai nilai siswanya kak,
Kurang terpikirkan juga saya 🙂
kak mau tanya, apa kah bisa metode knn untuk manajemen barang dengan klasifikasi kondisi barang yang di nilai?
Untuk masalah klasifikasi, menurut saya KKN dapat digunakan 🙂
Ka kalau
Temperaturnya 13 kecepatan anginnya 3 dan k=3
Itu hasil klasifikasinya gimana??
Diperoleh 3 tetangga terdekat
(15,5) Dingin Jarak 5
(10,0) Dingin Jarak 6
(20,3) Panas Jarak 7
Jadi, hasilnya dingin (Frekuensi terbanyak)
Semoga bermanfaat 🙂
Selamat malam kak
Mau tanya
Saya implementasi knn nilai k nya di mulai dari k 3 apakah tidak papa? Dan nantinya alasannya apa kalo dimulai dari k 3.. Kenapa kok tidak dari nilai k 1 ? Misal ada pertanyaan seperti itu bagaimana jawabya ya?
Kalau 1 itu namanya Nearest neighbours, tanpa k hasilnya pun terlihat tidak adil untuk data yang berjumlah di atas 10. Kemudian kenapa tidak 2, hal ini menghindari algoritma yang tidak konsisten, jika dalam pengujian, data terdekat beda-beda, algoritma akan mengambil k selanjutnya. Ini meningkatkan penggunaan memory secara menyeluruh untuk penambahan nilai k yang kemungkinan sering dilakukan
Semoga bermanfaat 🙂