
")
K-nearest neighbors atau knn adalah algoritma yang berfungsi untuk melakukan klasifikasi suatu data berdasarkan data pembelajaran (train data sets), yang diambil dari k tetangga terdekatnya (nearest neighbors). Dengan k merupakan banyaknya tetangga terdekat.
A. Cara Kerja Algoritma K-Nearest Neighbors (KNN)
K-nearest neighbors melakukan klasifikasi dengan proyeksi data pembelajaran pada ruang berdimensi banyak. Ruang ini dibagi menjadi bagian-bagian yang merepresentasikan kriteria data pembelajaran. Setiap data pembelajaran direpresentasikan menjadi titik-titik c pada ruang dimensi banyak.
A1. Klasifikasi Terdekat (Nearest Neighbor Classification)
Data baru yang diklasifikasi selanjutnya diproyeksikan pada ruang dimensi banyak yang telah memuat titik-titik c data pembelajaran. Proses klasifikasi dilakukan dengan mencari titik c terdekat dari c-baru (nearest neighbor). Teknik pencarian tetangga terdekat yang umum dilakukan dengan menggunakan formula jarak euclidean. Berikut beberapa formula yang digunakan dalam algoritma knn.
-
Euclidean Distance
Jarak Euclidean adalah formula untuk mencari jarak antara 2 titik dalam ruang dua dimensi.

-
Hamming Distance
Jarak Hamming adalah cara mencari jarak antar 2 titik yang dihitung dengan panjang vektor biner yang dibentuk oleh dua titik tersebut dalam block kode biner.
-
Manhattan Distance
Manhattan Distance atau Taxicab Geometri adalah formula untuk mencari jarak d antar 2 vektor p,q pada ruang dimensi n.
-
Minkowski Distance
Minkowski distance adalah formula pengukuran antar 2 titik pada ruang vektor normal yang merupakan hibridisasi yang menjeneralisasi euclidean distance dan mahattan distance.
Teknik pencarian tetangga terdekat disesuaikan dengan dimensi data, proyeksi, dan kemudahan implementasi oleh pengguna.
A2. Banyaknya k Tetangga Terdekat
Untuk menggunakan algoritma k nearest neighbors, perlu ditentukan banyaknya k tetangga terdekat yang digunakan untuk melakukan klasifikasi data baru. Banyaknya k, sebaiknya merupakan angka ganjil, misalnya k = 1, 2, 3, dan seterusnya. Penentuan nilai k dipertimbangkan berdasarkan banyaknya data yang ada dan ukuran dimensi yang dibentuk oleh data. Semakin banyak data yang ada, angka k yang dipilih sebaiknya semakin rendah. Namun, semakin besar ukuran dimensi data, angka k yang dipilih sebaiknya semakin tinggi.
A3. Algoritma K-Nearest Neighbors
- Tentukan k bilangan bulat positif berdasarkan ketersediaan data pembelajaran.
- Pilih tetangga terdekat dari data baru sebanyak k.
- Tentukan klasifikasi paling umum pada langkah (2), dengan menggunakan frekuensi terbanyak.
- Keluaran klasifikasi dari data sampel baru.
B. Contoh Aplikasi K Nearest Neighbors
Contoh berikut diambil dari buku "Data Science Algorithms in a Week" yang ditulis oleh Dávid Natingga.
Pada contoh ini, dilakukan klasifikasi suhu udara berdasarkan persepsi seseorang yang bernama Marry. Adapun klasifikasi suhu udara terdiri dari 2 persepsi yaitu Panas dan Dingin. Persepsi ini dapat diukur berdasarkan 2 variabel yaitu temperatur dalam derajat celcius dan kecepatan angin dalam km/h. Diperoleh data berikut,
| Temperatur Udara (ºC) | Kecepatan Angin (km/jam) | Klasifikasi atau Persepsi Marry |
| 10 | 0 | Dingin |
| 25 | 0 | Panas |
| 15 | 5 | Dingin |
| 20 | 3 | Panas |
| 18 | 7 | Dingin |
| 20 | 10 | Dingin |
| 22 | 5 | Panas |
| 24 | 6 | Panas |
Untuk contoh ini terbentuk ruang dimensi 2, yang berisi 2 kriteria yaitu temperatur udara dan kecepatan angin.
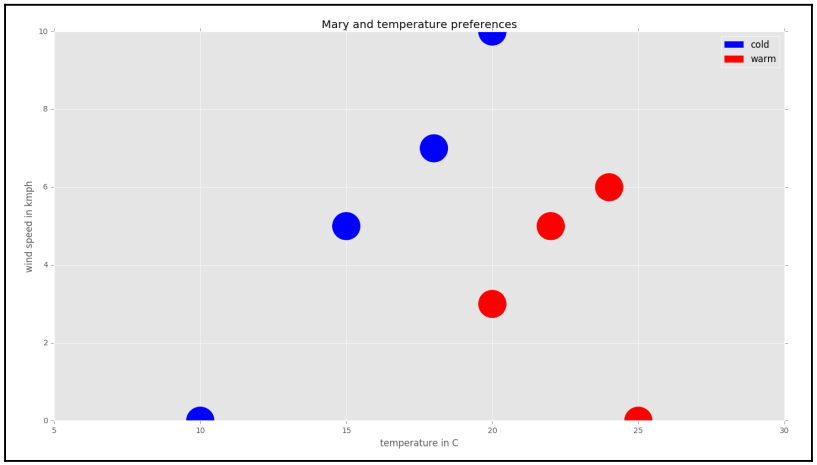
Pada proyeksi di atas sumbu vertikal adalah kecepatan angin, sumbu horizontal adalah temperatur suhu, warna biru adalah dingin, dan warna merah adalah panas.
Dari proyeksi di atas, dapat dilakukan klasifikasi data baru. Misalnya, Bagaimana persepsi Marry saat temperatur udara 16°C dan kecepatan angin 3 km/jam.
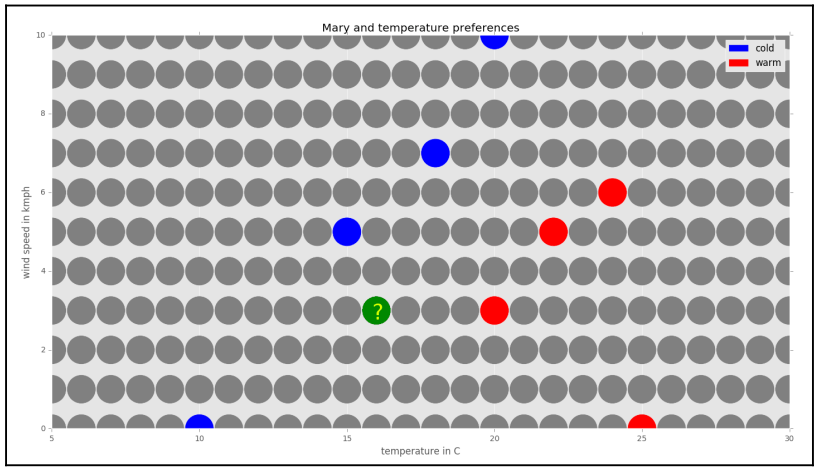
Proses pencarian tetangga terdekat
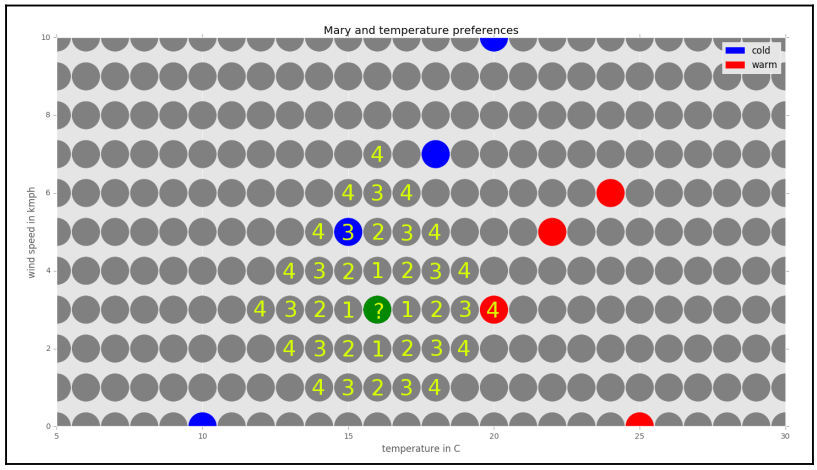
Dapat diketahui tetangga terdekatnya adalah titik c dingin dengan temperatur 15°C dan kecepatan angin 5 km/jam. Jadi berdasarkan pemilihan k = 1, klasifikasinya adalah dingin.
Dengan melakukan proses di atas terhadap semua titik, diperoleh proyeksi klasifikasi berikut.
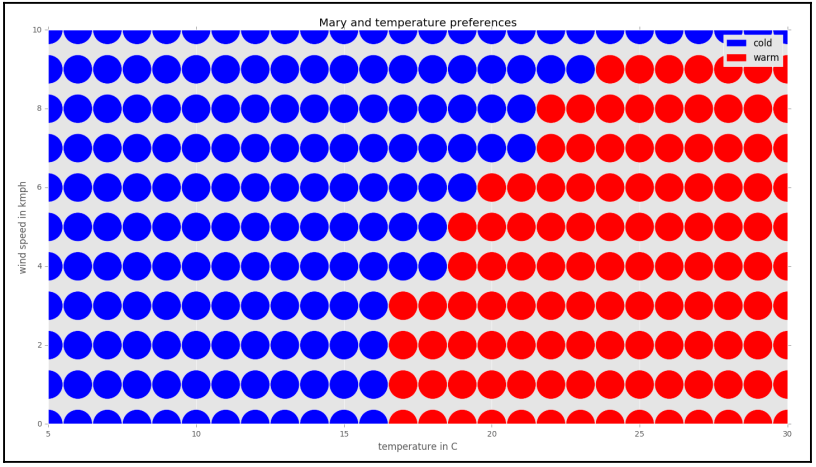
Catatan: Untuk pemilihan k lainnya, hasil klasifikasi ditentukan dengan frekuensi terbanyak. Misalnya k = 3, dengan titik terdekat dingin, panas, dingin. Hasil klasifikasi data baru tersebut adalah dingin.
Baca juga tutorial lainnya: Daftar Isi Machine Learning
Sekian artikel Pengertian dan Cara Kerja Algoritma K-Nearest Neighbors (KNN). Nantikan artikel menarik lainnya dan mohon kesediaannya untuk share dan juga menyukai halaman Advernesia. Terima kasih…



")


hai kak saya mau bertanya apakah KNN bisa diterapkan pada sebuah kasus Ecommerce untuk menentukan toko asli dan toko palsu? mohon penjelasan nya kak
Ka saya mau nanya, saya saat ini sedang melakukan penelitian mengenai tingkat kelulusan mahasiswa di universitas menggunakan KNN. data yang saya dapatkan hanya nama, nim, fakultas, jurusan, tanggal lulus dan IPK. saat ini datanya masih terpisah2 apakah harus saya satukan semua ? atau bagaimana ? mohon pencerahannya.
Terima Kasih
kak mau tanya apakah K-Nearest Neighbor ini termasuk ke dalam algoritma mobile tecnology atau kecerdasan buatan kak
Kak mau tanya, kalau datanya ada 15 atribut, dan beberapa berupa huruf bagaimana ya? apakah hurufnya dihiraukan di metode KNN?
contoh data :
b,39.83,0.5,u,g,m,v,0.25,t,f,0,f,s,00288,0, (kelas negatif)
a,22.50,11,y,p,q,v,3,t,f,0,t,g,00268,0,(kelas positif)
Hallo kak mau nanya, maksimal data yang digunakan agar bisa menggunakan metode KNN berapa ya kak?
apakah data sebanyak 365 bisa digunakan metode kkn?
kak mau nanya untuk prediksi stok obat2an di apotik menunggakan algoritma knn apakah bisa?
Halo kak, ijin bertanya untuk algoritma knn ini membutuhkan minimal berapa data ya kak? Terimakasih..
Itu disesuaikan dengan nilai k+1 putri
semoga membantu 🙂
apa adaa jasa pengerjaan untuk mencari K-Nearest Neighbor (KNN) KNN ya